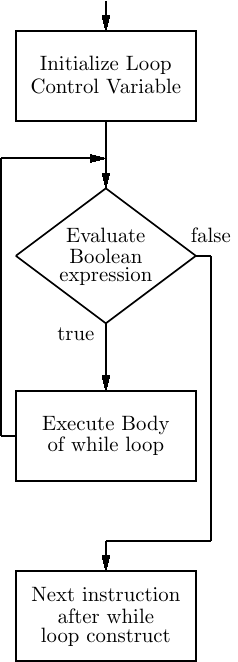
Figure 10.1: Flow chart of a while loop. The large diamond represents a binary decision that leads
to two possible paths, “true” or “false.” Notice the path that leads back to the top of the while loop
after the body has been executed.
The assembly language we have studied thus far is executed in sequence. In this chapter we will learn how to organize assembly language instructions to implement the other two required program flow constructs — repetition and binary decision.
Text string manipulations provide many examples of using program flow constructs, so we will use them to illustrate many of the concepts. Almost any program displays many text string messages on the screen, which are simply arrays of characters.
The algorithms we choose when programming interact closely with the data storage structure. As you probably know, a string of characters is stored in an array. Each element of the array is of type char, and in C the end of the data is signified with a sentinel value, the NUL character (see Table 2.3 on page 49).
Array processing is usually a repetitive task. The processing of a character string is a good example of repetition. Consider the C program in Listing 10.1.
The while statement on lines 13 – 17,
controls the execution of the statements within the {…} block.
The pointer variable is incremented with the
statement. Notice that this variable must be changed inside the {…} block. Otherwise, the boolean expression will always evaluate to true, giving an “infinite” loop.
It is important that you identify the variable that the while construct uses to control program flow — the Loop Control Variable (LCV). Make sure that the value of the LCV is changed within the {…} block. Note that there may be more than one LCV.
The way that the while construct controls program flow can be seen in the flow chart in Figure 10.1.
This flow chart shows that we need the following assembly language tools to construct a while loop:
We will explore instructions that provide these tools in the next three subsections.
Most arithmetic and logic instructions affect the condition code bits in the rflags register. (See page 470.) In this section we will look at two instructions that are used to set the condition codes to show the relationship between two values without changing either of them.
One is cmp (compare). The syntax is
|
| cmps | source, destination | |
where s denotes the size of the operand:
| s | meaning | number of bits |
| b | byte | 8 |
| w | word | 16 |
| l | longword | 32 |
| q | quadword | 64 |
| Intel® Syntax |
| cmp | destination, source |
The cmp operation consists of subtracting the source operand from the destination operand and setting the condition code bits in the rflags register accordingly. Neither of the operand values is changed. The subtraction is done internally simply to get the result and set the OF, SF, ZF, AF, PF, CF condition codes according to the result.
The other instruction is test. The syntax is
|
| tests | source, destination | |
where s denotes the size of the operand:
| s | meaning | number of bits |
| b | byte | 8 |
| w | word | 16 |
| l | longword | 32 |
| q | quadword | 64 |
| Intel® Syntax |
| test | destination, source |
The test operation consists of performing a bit-wise and between the two operands and setting the condition codes in the rflags register accordingly. Neither of the operand values is changed. The and operation is done internally simply to get the result and set the SF, ZF, and PF condition codes according to the result. The OF and CF are set to 0, and the AF value is undefined.
These instructions are used to alter the flow of the program depending on the settings of the condition code bits in the rflags register. The general format is
|
| jcc | label | |
where cc is a 1 – 4 letter sequence specifying the condition codes, and label is a memory location. Program flow is transferred to label if cc is true. Otherwise, the instruction immediately following the conditional jump is executed. The conditional jump instructions are listed in Table 10.1.
| instruction | action | condition codes |
| ja | jump if above | (CF = 0) ⋅ (ZF = 0) |
| jae | jump if above or equal | CF = 0 |
| jb | jump if below | CF = 1 |
| jbe | jump if below or equal | (CF = 1) + (ZF = 1) |
| jc | jump if carry | CF = 1 |
| jcxz | jump if cx register zero | |
| jecxz | jump if ecx register zero | |
| jrcxz | jump if rcx register zero | |
| je | jump if equal | ZF = 1 |
| jg | jump if greater | (ZF = 0) ⋅ (SF = OF) |
| jge | jump if greater or equal | SF = OF |
| jl | jump if less | SF≠OF |
| jle | jump if less or equal | (ZF = 1) + (SF≠OF) |
| jna | jump if not above | (CF = 1) + (ZF = 1) |
| jnae | jump if not above or equal | CF = 1 |
| jnb | jump if not below | CF = 0 |
| jnbe | jump if not below or equal | (CF = 0) ⋅ (ZF = 0) |
| jnc | jump if not carry | CF = 0 |
| jne | jump if not equal | ZF = 0 |
| jng | jump if not greater | (ZF = 1) + (SF≠OF) |
| jnge | jump if not greater or equal | SF≠OF |
| jnl | jump if not less | SF = OF |
| jnle | jump if not less or equal | (ZF = 0) ⋅ (SF = OF) |
| jno | jump if not overflow | OF = 0 |
| jnp | jump if not parity or equal | PF = 0 |
| jns | jump if not sign | SF = 0 |
| jnz | jump if not zero | ZF = 0 |
| jo | jump if overflow | OF = 1 |
| jp | jump if parity | PF = 1 |
| jpe | jump if parity even | PF = 1 |
| jpo | jump if parity odd | PF = 0 |
| js | jump if sign | SF = 1 |
| jz | jump if zero | ZF = 1 |
A good way to appreciate the meaning of the cc sequences in this table is to consider a very common application of a conditional jump:
If the value in the bl register is numerically above the value in the al register, or if they are equal, then program control transfers to the address labeled “somePlace.” Otherwise, program control continues with the movb instruction.
The differences between “greater” versus “above”, and “less” versus “below”, are a little subtle. “Above” and “below” refer to a sequence of unsigned numbers. For example, characters would probably be considered to be unsigned in most applications. “Greater” and “less” refer to signed values. Integers are commonly considered to be signed.
Table 10.2 lists four conditional jumps that are commonly used when processing unsigned values, and Table 10.3 lists four commonly used with signed values.
| instruction | meaning | immediately after a cmp … |
| ja | jump above | jump if destination is above source in sequence |
| jae | jump above or equal | jump if destination is above or in same place as source in sequence |
| jb | jump below | jump if destination is below source in sequence |
| jbe | jump below or equal | jump if destination is below or in same place as source in sequence |
| instruction | meaning | immediately after a cmp … |
| jg | jump greater | jump if destination is greater than source |
| jge | jump greater or equal | jump if destination is greater than or equal to source |
| jl | jump less | jump if destination is less than source |
| jle | jump less or equal | jump if destination is less than or equal to source |
Since most instructions affect the settings of the condition codes in the rflags register, each must be used immediately after the instruction that determines the conditions that the programmer intends to cause the jump.
The jump instructions bring up another addressing mode — rip-relative. 1
The offset, which can be positive or negative, is stored immediately following the opcode for the instruction in two’s complement format. Thus, the offset becomes a part of the instruction, similar to the immediate data addressing mode. Just like the immediate addressing mode, the offset is stored in little endian order in memory.
The following steps occur during program execution of a jcc instruction (recall Figure 6.5):
When a conditional jump instruction is assembled, the assembler computes the number of bytes from the jump instruction to the specified label. The assembler then subtracts the number of bytes in the jump instruction from the distance to the label to yield the offset. This computed offset is stored as part of the jump instruction. Each jump instruction has several forms, depending on the number of bytes that must be used to store the offset. Note that the offset is stored in two’s complement format to allow for negative jumps.
For example, if the offset will fit into eight bits the opcode for the je instruction is 7416, and it is 0f8416 if more than eight bits are required to store the offset (in which case the offset is stored in as a thirty-two bit value). The machine code is shown in Table 10.4 for four different target address offsets. Notice that the 32-bit offsets are stored in little endian order in memory.
| distance to target address | machine code |
| (bytes, decimal) | (hexadecimal) |
| +100 | 7462 |
| -100 | 749a |
| +300 | 0f8426010000 |
| -300 | 0f84cefeffff |
We also need an instruction that unconditionally transfers control to another location in the program. The instruction has three forms:
|
| jmp | label | |
|
| jmp | *register | |
|
| jmp | *memory | |
Program flow is transferred to the location specified by the operand.
The first form is limited to those situations where the distance, in number of bytes, to the target location will fit within a 32-bit signed integer. The addressing mode is rip-relative. That is, the 32-bit signed integer is added to the current value in the rip register. This is sufficient for most cases.
In the other two forms, the target address is stored in the specified register or memory location, and the operand is accessed indirectly. The address is an unsigned 64-bit value. The jmp instruction moves this stored address directly into the rip register, replacing the address that was in there. The “*” character is used to indicate “indirection.”
The three ways to use an unconditional jump are shown in Listing 10.2.
The most commonly used form is rip-relative as shown on line 19:
On lines 22 – 23 an address is loaded into a register, then the jump is made indirectly via the register to that address.
Lines 26 – 28 show how an address can be stored in memory, then the memory used indirectly for the jump.
Of course, the indirect techniques are not required in this simple example, but they might be needed for some programs.
We are now prepared to look at how a while loop is constructed at the assembly language level. As usual, we begin with the assembly language generated by the gcc compiler for the program in Listing 10.1, which is shown in Listing 10.3 with comments added.
Let us consider the loop:
Notice that after initializing the loop control variable it jumps to the condition test,
which is at the bottom of the loop:
Let us rearrange the instructions so that this is a true while loop — the condition test is at the top of the loop. The exit condition has been changed from jne to je for correctness. The original is on the left, the rearranged on the right:
Compiler’s version
Test at top of loop
We also see another version of the mov instruction on line 22 of the compiler’s version:
This instruction converts the data size from 8-bit to 32-bit, placing zeros in the high-order 24 bits, as it copies the byte from memory to the eax register. The memory address of the copied byte is in the rax register. (Yes, this instruction writes over the address in the register as it executes.)
The x86-64 architecture includes instructions for extending the size of a value by adding more bits to the left. There are two ways to do this:
Sign extension can be accomplished with the movs instruction:
|
| movssd | source, destination | |
where s denotes the size of the source operand and d the size of the destination operand. (Use the s column for d.)
| s | meaning | number of bits |
| b | byte | 8 |
| w | word | 16 |
| l | longword | 32 |
| q | quadword | 64 |
In the Intel syntax the instruction is movsx. The size of the data is determined by the operands, so the
size characters (b, w, l, or q) are not appended to the instruction, and the order of the operands is
reversed.
| Intel® Syntax |
| movsx | destination, source |
In some cases the Intel syntax is ambiguous. Intel-syntax assemblers use keywords to specify the data
size in such cases. For example, the nasm assembler uses
movsx destination, BYTE [source]
to move one byte and zero extend, and uses
movsx destination, WORD [source]
to move two bytes and sign extend.
Zero extension can be accomplished with the movz instruction:
|
| movzsd | source, destination | |
where s denotes the size of the source operand and d the size of the destination operand. (Use the s column for d.)
| s | meaning | number of bits |
| b | byte | 8 |
| w | word | 16 |
| l | longword | 32 |
| q | quadword | 64 |
In the Intel syntax the instruction is movzx The size of the data is determined by the operands, so the
size characters (b, w, l, or q) are not appended to the instruction, and the order of the operands is
reversed.
| Intel® Syntax |
| movzx | destination, source |
There is also a set of instructions that double the size of data in portions of the rax register, shown in Table 10.5. The doubling operation includes sign extention into the affected higher-order portion of the register.
| AT&T syntax | Intel® syntax | start | result |
| cbtw | cbw | byte in al | word in ax |
| cwtl | cwde | word in ax | long in eax |
| cltq | cdqe | lonq in eax | quad in rax |
Notice that these instructions do not explicitly specify any operands, but they may change the rax register. They do not affect the condition codes in the rflags register.
Returning to while loops, the general structure of a count-controlled while loop is shown in Listing 10.4.
This is not a complete program or even a function. It simply shows the key elements of a while loop.
Our assembly language version of a “Hello world” program in Listing 10.5 uses a sentinel-controlled while loop.
Consider the sequence on lines 26 – 28:
We had to move the pointer value into a register in order to dereference the pointer. These two instructions implement the C expression:
In particular, you have to move the address into a register, then dereference it with the “(register)” syntax.
There are two common errors when using the assembly language syntax.
to dereference the variable, ptr.
Neither do
nor
work to dereference the theString location. Unfortunately, the assembler may not consider any of these to be syntax errors, just an unnecessary set of parentheses. Therefore, you probably will not get an assembler error message, just incorrect program behavior.
This would compare a byte in the esi register itself with the value zero. Since there are four bytes in the esi register, this code will generate an assembler warning message because it does not specify which byte.
We also need to add one to the pointer variable so as to move it to the next character in the string. Adding one is a common operation, so there is an operator that simply adds one,
|
| incs | source | |
where s denotes the size of the operand:
| s | meaning | number of bits |
| b | byte | 8 |
| w | word | 16 |
| l | longword | 32 |
| q | quadword | 64 |
On line 35 of the program in Listing 10.5, incl is used to add one to the address stored in memory:
Subtracting one from a counter is also a common operation. The dec instruction subtracts one from an operand and sets the rflags register accordingly. The operand can be a register or a memory location.
|
| decs | source | |
where s denotes the size of the operand:
| s | meaning | number of bits |
| b | byte | 8 |
| w | word | 16 |
| l | longword | 32 |
| q | quadword | 64 |
A decl instruction is used on line 27 in Listing 10.6 to both subtract one from the counter variable and to set the condition codes in the rflags register for the jg instruction.
This is clearly better than using
This program also demonstrates how to implement a do-while loop.
We now know how to implement two of the primary program flow constructs — sequence and repetition. We continue on with the third — binary decision. You know this construct from C/C++ as the if-else.
We start the discussion with a common example — a simple program that asks the user whether changes should be saved or not (Listing 10.7). This example program does not do anything, so there really is nothing to change, but you have certainly seen this construct. (As usual, this program is meant to illustrate concepts, not good C/C++ programming practices.)
Let’s look at the flow of the program that the if-else controls.
The program control flow of the if-else construct is illustrated in Figure 10.2.
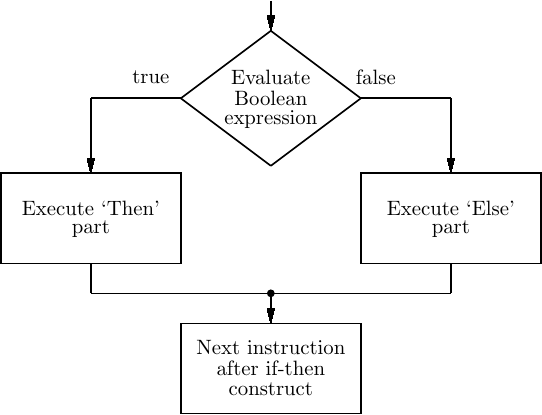
We already know all the assembly language instructions needed to implement the if-else in Listing 10.7. The important thing to note is that there must be an unconditional jump at the end of the “then” block to transfer program flow around the “else” block. The assembly language generated for this program is shown in Listing 10.8.
The general structure of an if-else construct is shown in Listing 10.9.
This is not a complete program or even a function. It simply shows the key elements of an if-else construct.
Our assembly language version of the yes/no program in Listing 10.10 follows this general pattern. It, of course, uses more meaningful labels than what the compiler generated.
The exit from the while loop on line 59
jumps to the end of the “then” block of the if-else statement, which then jumps to the end of the entire if-else statement:
In this particular program we could gain some efficiency by using
on line 59. But this very slight efficiency gain comes at the expense of good software engineering. In general, there could be more processing to do after the while loop in the “then” block of the if-else statement. The real danger here is that additional processing will be added during the program’s maintenance phase and the programmer will forget to change the structure. Good, easy to read structure is almost always better than execution efficiency.
Another common programming problem is to check to see if a variable is within a certain range. This requires a compound boolean expression, as shown in the C program in Listing 10.11.
Each condition of the boolean expression generally requires a separate comparison/conditional jump pair. The best way to see this is to study the compiler-generated assembly language code of the numeral checking program in Listing 10.12.
In particular, notice that the decision regarding whether the character entered by the user is a numeral or not is made on the lines:
Consulting Table 2.3 on page 49 we see that the program first compares the character entered by the user with the ascii code for the numeral “9” (5710 = 3916). If the character is numerically greater, the program jumps to .L5, which is the beginning of the “else” part. Then the character is compared to the ASCII code for the character “/”, which is numerically one less that the ascii code for the numeral “0” (4810 = 3016). If the character is numerically equal to or less than, the program also jumps to .L5.
If neither of these conditions causes a jump to the “else” part, the program simply continues on to execute the “then” part. At the end of the “then” part, the program skips over the “else” part to the end of the program:
Consider the boolean expression use for the if-else conditional:
On lines 35 and 36 in the assembly language,
we see that the test for ’0’ is never made if (response <= ’9’) is false.
This is called short-circuit evaluation in C/C++. When connecting boolean tests with the && and || operators, each of the boolean tests is executed one at a time from left to right. If the overall result of the expression — true or false — is known before all the tests are made, the remaining tests are not executed. This is one of the most important reasons for not writing boolean expressions that include side effects; the operation that produces a needed side effect may never get executed.
Many binary decisions are very simple. For example, the decision in Listing 10.7 could be written:
This code segment assigns an address to the ptr variable. If the condition, response == ’y’, is true, then the address in the ptr variable is written over with another address. This could be written in assembly language (see Listing 10.10) as:
The x86-64 architecture provides a conditional move instruction, cmovcc, for simple if constructs like this. The general format is
|
| cmovcc | source, destination | |
where cc is a 1 – 4 letter sequence specifying the settings of the condition codes. Similar to the conditional jump instructions, the conditional data move takes place if the status flag settings are true, and does not if they are false.
Possible letter sequences are the same as for the conditional jump instructions listed in Table 10.1 on page 679. The source operand can be either a register or a memory location, and the destination must be a register. Unlike other data movement instructions, the cmovcc instruction does not use the operand size suffix; the size is implicitly specified by the size of the destination register.
The conditional move instruction would allow the above assembly language to be written with a cmove instruction, where the “e” means “equal” (see Table 10.1).
Although this actually increases the average number of instructions executed, it allows the CPU to make more efficient use of the pipeline. So a conditional move may provide faster program execution by eliminating possible pipeline inefficiencies caused by a conditional jump. See for example [28], [31], and [34].
This summary shows the assembly language instructions introduced thus far in the book. The page number where the instruction is explained in more detail, which may be in a subsequent chapter, is also given. This book provides only an introduction to the usage of each instruction. You need to consult the manuals ([2] – [6], [14] – [18]) in order to learn all the possible uses of the instructions.
| data movement: | ||||
| opcode | source | destination | action | page |
| cbtw | convert byte to word, al → ax | 696 | ||
| cwtl | convert word to long, ax → eax | 696 | ||
| cltq | convert long to quad, eax → rax | 696 | ||
| cmovcc | %reg/mem | %reg | conditional move | 706 |
| movs | $imm/%reg | %reg/mem | move | 506 |
| movs | mem | %reg | move | 506 |
| movsss | $imm/%reg | %reg/mem | move, sign extend | 693 |
| movzss | $imm/%reg | %reg/mem | move, zero extend | 693 |
| popw | %reg/mem | pop from stack | 566 | |
| pushw | $imm/%reg/mem | push onto stack | 566 | |
| s = b, w, l, q; w = l, q; cc = condition codes
| ||||
| arithmetic/logic:
| ||||
| opcode | source | destination | action | page |
| adds | $imm/%reg | %reg/mem | add | 607 |
| adds | mem | %reg | add | 607 |
| cmps | $imm/%reg | %reg/mem | compare | 676 |
| cmps | mem | %reg | compare | 676 |
| decs | %reg/mem | decrement | 699 | |
| incs | %reg/mem | increment | 698 | |
| leaw | mem | %reg | load effective address | 579 |
| subs | $imm/%reg | %reg/mem | subtract | 612 |
| subs | mem | %reg | subtract | 612 |
| tests | $imm/%reg | %reg/mem | test bits | 676 |
| tests | mem | %reg | test bits | 676 |
| s = b, w, l, q; w = l, q
| ||||
| program flow control:
| |||
| opcode | location | action | page |
| call | label | call function | 546 |
| ja | label | jump above (unsigned) | 683 |
| jae | label | jump above/equal (unsigned) | 683 |
| jb | label | jump below (unsigned) | 683 |
| jbe | label | jump below/equal (unsigned) | 683 |
| je | label | jump equal | 679 |
| jg | label | jump greater than (signed) | 686 |
| jge | label | jump greater than/equal (signed) | 686 |
| jl | label | jump less than (signed) | 686 |
| jle | label | jump less than/equal (signed) | 686 |
| jmp | label | jump | 691 |
| jne | label | jump not equal | 679 |
| jno | label | jump no overflow | 679 |
| jcc | label | jump on condition codes | 679 |
| leave | undo stack frame | 580 | |
| ret | return from function | 583 | |
| syscall | call kernel function | 587 | |
| cc = condition codes
| |||
| register direct: | The data value is located in a CPU register. |
|
| syntax: name of the register with a “%” prefix. |
|
| example: movl %eax, %ebx |
| immediate data: | The data value is located immediately after the instruction. Source operand only. |
|
| syntax: data value with a “$” prefix. |
|
| example: movl $0xabcd1234, %ebx |
| base register plus offset: | The data value is located in memory. The address of the memory location is the sum of a value in a base register plus an offset value. |
|
| syntax: use the name of the register with parentheses around the name and the offset value immediately before the left parenthesis. |
|
| example: movl $0xaabbccdd, 12(%eax) |
| rip-relative: | The target is a memory address determined by adding an offset to the current address in the rip register. |
|
| syntax: a programmer-defined label |
|
| example: je somePlace |
(§10.1) Verify on paper that the machine instructions in Table 10.4 actually cause a jump of the number of bytes shown (in decimal) when the jump is taken.
(§10.1) Enter the program in Listing 10.2 and verify that the jump to here1 uses the rip-relative addressing mode, and the other two jumps use the direct address. Hint: Produce a listing file for the program and use gdb to examine register and memory contents.
(§10.1) Enter the program in Listing 10.5, changing the while loop to use eax as a pointer:
This would seem to be more efficient than reading the pointer from memory each time through the loop. Use gdb to debug the program. Set a break point at the call instruction and another break point at the incl instruction. Inspect the registers each time the program breaks into gdb. What is happening to the value in eax? Hint: Read what the “man 2 write” shell command has to say about the write system call function. This exercise points out the necessity of understanding what happens to registers when calling another function. In general, it is safer to use local variables in the stack frame.
(§10.1) Assume that you do not know how many numerals there are, only that the first one is ’0’ and the last one is ’9’ (the character “0” and character “9”). Write a program in assembly language that displays all the numerals, 0 – 9, on the screen, one character at a time. Use only one byte in the .data segment for storing a character; do not allocate a separate byte for each numeral.
(§10.1) Assume that you do not know how many upper case letters there are, only that the first one is ’A’ and the last one is ’Z’. Write a program in assembly language that displays all the upper case letters, A – Z, on the screen, one character at a time. Use only one byte in the .data segment for storing a character; do not allocate a separate byte for each numeral.
(§10.1) Assume that you do not know how many lower case letters there are, only that the first one is ’a’ and the last one is ’z’. Write a program in assembly language that displays all the lower case letters, a – z, on the screen, one character at a time. Use only one byte in the .data segment for storing a character; do not allocate a separate byte for each numeral.
(§10.1) Enter the following C program and use the “-S” option to generate the assembly language:
Identify the loop that performs the actual multiplication. Write an equivalent C program that uses a while loop instead of the for loop, and also generate the assembly language for it. Do the loops differ? If so, how?
(§10.2) Enter the C program in Listing 10.7 and get it to work. Do you see any odd behavior when the program terminates? Can you fix it? Hint: When the program prompts the user, how many keys did you press? What was the second key press?
(§10.2) Enter the program in Listing 10.10 and get it to work.
(§10.2) Write a program in assembly language that displays all the printable characters that are neither numerals nor letters on the screen, one character at a time. Don’t forget that the space character, ’ ’, is printable. Do not display the DEL character. Use only one byte for storing a character; do not allocate a separate byte for each character.
Use only one while loop in this program. You will need an if-else construct with a compound boolean conditional statement.
(§10.2) Write a program in assembly language that
prompts the user to enter a text string,
reads the user’s input into a char array,
echoes the user’s input string,
increments each character in the string to the next character in the ASCII sequence, with the last printable character “wrapping around” to the first printable character, and
displays the modified string.
(§10.2) Write a program in assembly language that
prompts the user to enter a text string,
reads the user’s input into a char array,
echoes the user’s input string,
decrements each character in the string to the previous character in the ASCII sequence, with the first printable character “wrapping around” to the last printable character, and
displays the modified string.
(§10.2) Write a program in assembly language that
instructs the user,
prompts the user to enter a character,
reads the user’s input into a char variable,
if the user enters a ’q’, the program terminates,
if the user enters a numeral, the program echoes the numeral the number of times represented by the numeral plus one, and
any other printable character is echoed just once.
The program continues to run until the user enters a ’q’.
For example, a run of the program might look like (user input is boldface):
A single numeral, N, is echoed N+1 times, other characters are echoed
once. ’q’ ends program.
Enter a single character: a
You entered: a
Enter a single character: Z
You entered: Z
Enter a single character: 5
You entered: 5
You entered: 5
You entered: 5
You entered: 5
You entered: 5
You entered: 5
Enter a single character: %
You entered: %
Enter a single character: q
End of program.