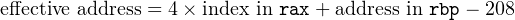
An essential part of programming is determining how to organize the data. Homogeneous data is often grouped in an array, and heterogeneous data in a struct. In this chapter, we study how both these data structures are implemented.
An array in C/C++ consists of one or more elements, all of the same type, arranged contiguously in memory. To access an element in an array you need to specify two address-related items:
For example, given the declaration:
you can store an integer, say 123, in the ith element with the statement
In this example the beginning of the array is specified by using the name, and the number of the element is specified by the […] syntax, as illustrated by the program in Listing 13.1.
We would expect this program to allocate 4 × 50 = 200 bytes for myArray, plus 4 bytes for i in the local variable area. Indeed, the gcc-generated assembly language in Listing 13.2 shows that this total (204) has been increased to a multiple of sixteen, and 224 bytes have been allocated in the stack frame.1
Next, we see that the number of the element that is being accessed, 25, is stored in the variable i. Then it is loaded into eax and converted from 32-bit to 64-bit.
The next instruction
uses an addressing mode for the destination that is new to you, indexed. The syntax in the GNU assembly language is
|
| offset(base_register_name, index_register_name, scale_factor) | |
| Intel® Syntax | [base_register_name + index_register_name * scale_factor + offset] | |
When it is zero, the offset is not required.
| Intel® Syntax | [rdx + rax*4 - 16] |
The indexed addressing mode allows us to specify
in one instruction. The number of bytes in each element can be 1, 2, 4, or 8. Both registers, the beginning address register and the index register, must be the same size. (Hence the cltq instruction on line 14 of Listing 13.2 to convert the index value from a 32 to 64 bits in the rax register.)
So from the destination operand of the instruction on line 15, we can see that
Thus, the address of the element in the array is given by
|
|
Now that we know how a single array element is accessed, let us see how an entire array is processed.
The gcc compiler generated the assembly language shown in Listing 13.4 for this array clearing program.
We can see from line 17
that the address of the first element of this array is 0 ∗ 4 − 48 = −48 from the address in rbp, and the address of the last element is 9 ∗ 4 − 48 = −12 from the address in rbp. Since this function does not call any others, the array is stored in the red zone.
Indexing through the array is accomplished by loading the current value of the index variable into the rax register. Although this example simply increments the index through the array, you can see that the value used to index the array element is independent of maintaining the beginning address of the array.
The third value in the parentheses, 4, allows you to use the actual element number as the array index. This is clearly more convenient — hence, less error prone — than having to compute the number of bytes from the beginning of the array using the index value.
If we did not have this addressing mode, we would have to do something like:
Although this is logically correct, it requires two more instructions and uses more registers.
Listing 13.5 shows the equivalent program written in assembly language.
This version uses a do-while loop instead of a while loop entered at the bottom. The index and the address of the beginning of the array are maintained in registers.
Using a register for the index value presents a potential problem. Recall that some registers are guaranteed to be preserved by a function (Table 6.4, page 469). We have used r12 for the print do-while loop in this program because it calls another function — printf. The current value of index must be copied to the correct argument register for the call to printf:
Although the operating system probably does not depend on registers being saved, we have done so in this program:
and:
just to be safe.
An array is useful for grouping homogeneous data items that are of the same data type. A record (struct in C/C++) is used for grouping heterogeneous data items, which may be of the same or different data types. For example, an array is probably better for storing a list of test scores in a program that works with the ith test score, but a struct might be better for storing the coordinates of a point on an x − y graph.
The data elements in a struct are usually called fields. Accessing a field in a struct also requires two address-related items:
Consider the C program in Listing 13.6
Assignment to each of the three fields in the “x” struct is:
The name of the struct variable is specified first, followed by a dot (.), followed by the field name. The field names and their individual data types are declared between the {…} pair of the struct declaration.
The amount of memory required by a struct variable is equal to the sum of the amount of memory required by each of its fields. Thus in the above program, the amount of memory required is:
| aByte: | 1 byte |
| anInt: | 4 bytes |
| anotherByte: | 1 byte |
| total = | 6 bytes |
If we were to allocate these six bytes of memory without some thought, the first char variable could occupy the first byte, the int variable the next four bytes, and the second char variable the following byte. That is, relative to the address of the beginning of the struct,
However, the ABI [25] specifies that the alignment of each element should be the same as that of the “most strictly aligned component.” In this example the int element should be aligned on a 4-byte boundary. So even though the char elements only require one byte, they should also be aligned on 4-byte boundaries. Also, as explained in Section 8.5 (page 586), we should allocate memory in multiples of sixteen for local variables (see Exercise 13-4). These requirements suggest that each struct variable will be allocated on the stack as shown in Figure 13.1.
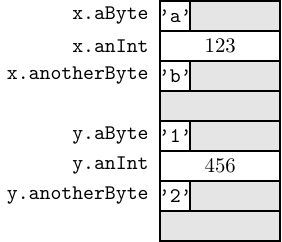
Thus we see that each of the struct variables in Listing 13.6 requires that we allocate sixteen bytes in the stack frame.
The next issue is how to access each of the fields in these two structs. You learned in Section 9.1 (page 601) that assignment in C is implemented with the mov instruction. So in this program assignment at the assembly language level is implemented:
The base register plus offset addressing mode (page 575) provides a convenient way to access each field in a struct. Simply load the address of the struct variable into a register, then use the offset of the field. We can see how the compiler has implemented this in Listing 13.7.
The compiler allocated 48 bytes in the stack frame. Thirty-two are for the two struct variables. The additional sixteen are needed for passing the seventh argument to the printf function (line 29), while maintaining 16-byte addressing of the stack pointer. Rather than load the address of each struct into a register, the compiler has computed the total offset to each of the fields in each of the structs.
As usual, we equate symbolic names to these numbers when writing in assembly language. We have tried to make our assembly language version (Listing 13.8) a little more readable than the version generated by gcc.
The version written in assembly language loads the address of a struct variable into a register before accessing the fields. This allows the use of the symbolic names for each field:
and:
This technique would be necessary with, say, an array of structs or a function that takes an address of a struct as an argument.
The general rules for passing arguments to functions are:
While C++ supports pass by reference for output parameters, C does not. In C, a pass by reference is simulated by passing a pointer to the variable to the function. Then the function can change the variable, thus affecting an output. At the assembly language level, pass by reference is implemented in C++ by passing a pointer, so these two rules can be restated:
Some languages, e.g., ADA, also support passing an “update.” In this case the function replaces the original value with a new value that depends upon the original value. Passing an argument for update is also implemented by passing its address.
There is an important exception to the rule of passing a copy for inputs. When the amount of data is large, making a copy of it is inefficient. So we organize it into a single entity and pass the address of that entity.
The most common example of this is an array. In fact, it is so common that in C arrays are automatically passed by address. Thus, in C/C++
means that x is passed by value and y is passed by address.
Another common example of passing a possibly large amount of data as input to a function is a struct. Of course, not all structs are large. And it is possible to pass the value in a single struct field, but the main reason for organizing data into a struct format is usually to treat several pieces of data as a more or less single unit.
Since structs are not automatically passed by address in C, we must use the address-of operator (&) on the name of the struct variable if we wish to avoid making a copy of the entire variable on the stack. The technique is exactly the same as passing an address of a simple variable.
Let us rewrite the C program from Listing 13.6 such that the main function calls another function to fill the two structs. In this example, the structs must be passed by address because the function, loadStruct, outputs values to them. This new version is shown in Listing 13.9.
In Listing 13.10 we examine the compiler-generated assembly language for the loadStruct function.
The type declaration in the function signature, struct theTag* aStruct, together with the struct definition in the header file, loadStruct1.h, tell the compiler what offsets to use for the struct fields on lines 15, 18, and 21.
We have already covered all the assembly language instructions and addressing modes needed to express the program in Listing 13.9 in assembly language. However, the .include assembler directive will make things much easier. The syntax is
which causes the assembler to insert everything in the file named “filename” into the source at the point of the .include directive. This assembler directive is essentially the same as the #include directive in C/C++. The assembly language version of our structPass program is shown in Listing 13.11.
Pay particular attention to the header file, loadStruct.h, which defines the offset to each field within the struct and provides overall size of the struct. This header file must be .included in any file that uses the struct.
Note that specifying the overall size of the struct makes it easier to allocate space for it. For example, we use
in Listing 13.11 to compute the offsets to the x and y variables in the stack frame.
The number in main,
and its use,
deserve some discussion here. After allocating space for the two structs on the stack, there is no way to know if the stack pointer is aligned on a 16-byte boundary. If it is not, the lowest-order four bits will be non-zero. The andq instruction sets these bits to zero, thus rounding the address down to the next lower 16-byte address boundary. Notice that this works because the stack grows toward numerically lower addresses.
The prologue and epilogue in loadStruct are not really needed in this simple function. But it is good to get in the habit of coding them into all your functions. It certainly has a negligible effect on execution time, and they help establish a structure to the function if it is ever changed.
In C++ the data that defines an instance of an object is organized as a struct. The name of the object is essentially the name of a struct variable. The class member functions have direct access to the struct’s fields, even if these fields are private data members. This direct access is implemented by passing the address of the object (the struct variable) as an implicit argument to the member function. In our environment, it is passed as the first (the left-most) argument, but it does not appear in the argument list.
Let’s look at a simple fraction class (Listing 13.12) as an example. The programs in this section assume the existence of the functions:
Let us consider the main function and see how arguments are passed on the stack. Recall that declaring an object in C++
calls the constructor function. As we said above, the address of the object (actually a struct) is passed to the constructor function, even though it is not explicitly stated in the object declaration statement. When program flow is passed to the constructor, the address of the x object is placed in the rdi register. The same thing occurs when the other member functions are called. The add member function takes an explicit argument, which is actually the second argument to the function, so is passed in the rsi register.
Before showing how the program of Listing 13.12 could be implemented in assembly language, we look at a C implementation, since we already know a lot about the transition from C to assembly language.
In C, the member data would be explicitly implemented as a struct. Implementing the member functions in C may seem very straightforward, but there is an important issue to consider — how do the member functions gain access to the data members? Since the data members are organized as a struct, passing its address as an argument to the member functions will allow each of them access to the data members. This is effectively what C++ does. The address of the “object” (actually, a struct) is passed as an implicit argument to each member function.
Another issue arises if you think about the possible names of member functions. Different C++ classes can have the same member function names, but functions in C do not belong to any class, so each must have a unique name. (Actually, “free” functions in C++ must also have unique names.) The C++ compiler takes care of this by adding the class name to the member function name. This is called name mangling. (There is no standard for how this is actually done, so each compiler may do it differently.) We do our own “name mangling” for the C version of the program as shown in Listing 13.13.
Notice the use of the this pointer in the C equivalents of the “member” functions. Its place in the parameter list coincides with the “implicit” argument to C++ member functions — that is, the address of the object. The this pointer is implicitly available for use within C++ member functions. Its use depends upon the specific algorithm. Listing 13.13 should give you a good idea of how C++ implements objects.
From the C version in Listing 13.13 it is straightforward to move to the assembly language version in Listing 13.14.
The “header” file, fraction.h, contains offsets for the fields of the struct that defines the state variables for a fraction object. Notice on line 8 that it includes a symbolic name for the size of the object.
This makes it easier to define offsets in the stack frame in main:
We then do:
technique to allocate space on the stack and make sure the stack pointer is on a 16-byte boundary.
In the fraction constructor function we see the use of the field names that are defined in the header file to access the state variables of the object:
The fraction_add function is a leaf function. So we use the red zone for saving the this pointer:
Be careful not to use the red zone in non-leaf functions.
This summary shows the assembly language instructions introduced thus far in the book. The page number where the instruction is explained in more detail, which may be in a subsequent chapter, is also given. This book provides only an introduction to the usage of each instruction. You need to consult the manuals ([2] – [6], [14] – [18]) in order to learn all the possible uses of the instructions.
| data movement: | ||||
| opcode | source | destination | action | page |
| cbtw | convert byte to word, al → ax | 696 | ||
| cwtl | convert word to long, ax → eax | 696 | ||
| cltq | convert long to quad, eax → rax | 696 | ||
| cwtd | convert word to long, ax → dx:ax | 786 | ||
| cltd | convert long to quad, eax → edx:eax | 786 | ||
| cqto | convert quad to octuple, rax → rdx:rax | 786 | ||
| cmovcc | %reg/mem | %reg | conditional move | 706 |
| movs | $imm/%reg | %reg/mem | move | 506 |
| movs | mem | %reg | move | 506 |
| movsss | $imm/%reg | %reg/mem | move, sign extend | 693 |
| movzss | $imm/%reg | %reg/mem | move, zero extend | 693 |
| popw | %reg/mem | pop from stack | 566 | |
| pushw | $imm/%reg/mem | push onto stack | 566 | |
| s = b, w, l, q; w = l, q; cc = condition codes
| ||||
| arithmetic/logic:
| ||||
| opcode | source | destination | action | page |
| adds | $imm/%reg | %reg/mem | add | 607 |
| adds | mem | %reg | add | 607 |
| ands | $imm/%reg | %reg/mem | bit-wise and | 747 |
| ands | mem | %reg | bit-wise and | 747 |
| cmps | $imm/%reg | %reg/mem | compare | 676 |
| cmps | mem | %reg | compare | 676 |
| decs | %reg/mem | decrement | 699 | |
| divs | %reg/mem | unsigned divide | 777 | |
| idivs | %reg/mem | signed divide | 784 | |
| imuls | %reg/mem | signed multiply | 775 | |
| incs | %reg/mem | increment | 698 | |
| leaw | mem | %reg | load effective address | 579 |
| muls | %reg/mem | unsigned multiply | 769 | |
| negs | %reg/mem | negate | 789 | |
| ors | $imm/%reg | %reg/mem | bit-wise inclusive or | 747 |
| ors | mem | %reg | bit-wise inclusive or | 747 |
| sals | $imm/%cl | %reg/mem | shift arithmetic left | 756 |
| sars | $imm/%cl | %reg/mem | shift arithmetic right | 751 |
| shls | $imm/%cl | %reg/mem | shift left | 756 |
| shrs | $imm/%cl | %reg/mem | shift right | 751 |
| subs | $imm/%reg | %reg/mem | subtract | 612 |
| subs | mem | %reg | subtract | 612 |
| tests | $imm/%reg | %reg/mem | test bits | 676 |
| tests | mem | %reg | test bits | 676 |
| xors | $imm/%reg | %reg/mem | bit-wise exclusive or | 747 |
| xors | mem | %reg | bit-wise exclusive or | 747 |
| s = b, w, l, q; w = l, q
| ||||
| program flow control:
| |||
| opcode | location | action | page |
| call | label | call function | 546 |
| ja | label | jump above (unsigned) | 683 |
| jae | label | jump above/equal (unsigned) | 683 |
| jb | label | jump below (unsigned) | 683 |
| jbe | label | jump below/equal (unsigned) | 683 |
| je | label | jump equal | 679 |
| jg | label | jump greater than (signed) | 686 |
| jge | label | jump greater than/equal (signed) | 686 |
| jl | label | jump less than (signed) | 686 |
| jle | label | jump less than/equal (signed) | 686 |
| jmp | label | jump | 691 |
| jne | label | jump not equal | 679 |
| jno | label | jump no overflow | 679 |
| jcc | label | jump on condition codes | 679 |
| leave | undo stack frame | 580 | |
| ret | return from function | 583 | |
| syscall | call kernel function | 587 | |
| cc = condition codes
| |||
| register direct: | The data value is located in a CPU register. |
|
| syntax: name of the register with a “%” prefix. |
|
| example: movl %eax, %ebx |
| immediate data: | The data value is located immediately after the instruction. Source operand only. |
|
| syntax: data value with a “$” prefix. |
|
| example: movl $0xabcd1234, %ebx |
| base register plus offset: | The data value is located in memory. The address of the memory location is the sum of a value in a base register plus an offset value. |
|
| syntax: use the name of the register with parentheses around the name and the offset value immediately before the left parenthesis. |
|
| example: movl $0xaabbccdd, 12(%eax) |
| rip-relative: | The target is a memory address determined by adding an offset to the current address in the rip register. |
|
| syntax: a programmer-defined label |
|
| example: je somePlace |
| indexed: | The data value is located in memory. The address of the memory location is the sum of the value in the base_register plus scale times the value in the index_register, plus the offset. |
|
| syntax: place parentheses around the comma separated list (base_register, index_register, scale) and preface it with the offset. |
|
| example: movl $0x6789cdef, -16(%edx, %eax, 4) |
(§13.1) Write a program in assembly language that allocates a twenty-five element integer array and stores the index value in each element. That is, the first element will be assigned zero, the second element one, etc. Use four-byte integers.
After the array has been completely initialized, display the contents of the array in a column.
(§13.1) Write a program in assembly language that allocates a ten element integer array and prompts the user to enter an integer to be stored in each element of the array. Use four-byte integers.
After the user’s values have been stored in the array, compute the sum of the integers. (Do not accumulate the sum as the numbers are entered.) Display the sum.
(§13.1) Write a program in assembly language that allocates a ten element integer array and prompts the user to enter an integer to be stored in each element of the array. Use four-byte integers.
After the user’s values have been stored in the array, compute the average of the integers. (Do not accumulate the sum as the numbers are entered.) Display the average.
(§13.2) Modify the program in Listing 13.6 so that it displays the total number of bytes allocated for the struct. Hint: use the C sizeof operator.
(§13.2) Modify the program of Exercise 13-4 such that it also displays the offset of each field within a struct. Hint: use the C & operator to get addresses.
(§13.2) Enter the program in Listing 13.8 and make sure that you understand how it works.
(§13.3) Enter the three files from Listing 13.11 and get the program to work.
Create a makefile to assemble and link the files into a program.
Using the debugger, gdb, set breakpoints in the main function at each call to loadStruct and at the instruction immediately following each call.
Use the debugger to observe the values that are stored in the fields of the aByte, anInt, and anotherByte fields each time loadStruct is called. Hint: Note the address in rdi just before executing each function call.
(§13.3) Modify the program in Listing 13.8 such that it has separate functions for:
Add two more struct variables to the program. Your program will then call the first function three times, once for each variable. Then it calls the second function three times, also once for each variable.
(§13.3) Write a program in assembly language that allocates three variables of the type:
That is, each variable will have two fields, one for the name of the item, and one for its cost.
The user will be prompted to enter the name and cost of each item, and the user’s input will be stored in the respective variables.
After the data for all three items is entered, the program will list the name and cost of each of the three items and then display the total cost for all three items.
(§13.4) Implement the program in Listing 13.14 such that it allows the user to enter an integer value to be added to the fraction.
(§13.4) Modify the program in Exercise 13-10 such that it allows the user to enter a fractional value, then adds the two fractions.
(§13.4) Write a program that allows the user to maintain an address book. Each entry into the address book should allow the user to enter
The user should be able to display the entries.
(§13.4) Modify the program in Exercise 13-12 so that the user can sort the address book entries on any of the five fields.
(§13.4) Write a program that allows the user to set up and maintain two bank accounts. Each account should have a unique account name. The user should be able to credit or debit the account.
(§13.4) Modify the program in Exercise 13-14 so that it requires a pin number in order to access each of the bank accounts.